I like the for dummies books. They are easy to read and understand. I try to do the same with this post. I hope you will find it useful for learning concepts about observability. Observability in a nutshell. (I’ll need to lookup how thumbnails work in Hugo with the Cactus theme.)
Video
Script
Hi all, Curious minds!
In the last couple of weeks, I had the opportunity to learn about a new Observability and Security tool.
When I used it end learned about its toolset, I was more and more excited about what else can it do. But I will not talk about them in this video.
Maybe I had more time to learn about toolings, or I have more experience in observability, but I found out that what is easily understandable for me around Security and Observability may not be so evident to others. In this video, I try to share my view, which can help you learn more and even quicker when you are facing a new tool.
What is Observability?
Every tool has its own definition. I will leave some examples in a blog post about this topic. My approach is a bit different, and It does not really connect to concrete tools.
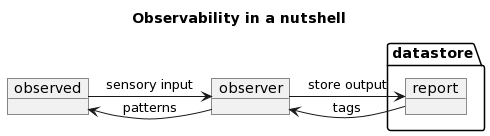
I say Observability is the most fundamental way we can learn and react. It is more related to how humans learn. And the steps are the following:
- We observe with our Sensory Input
- Learn and recognize patterns
- Store this information for later use
- Create tags and assign them to objects
- Iterate on the process
You have the sensory input like your eyes and ears. If you find my example valuable, then you may store the information in your memory.
Now I just need to show you the pattern to recognize and the required tags. And I will iterate on the concept to show you a different perspective.
The pattern of observability:
The tags of observability:

Observed examples:
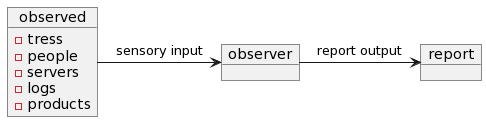
Observer examples:
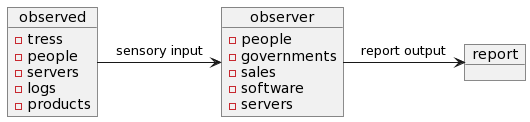
Report examples:

Reports are not helpful if we don’t store them somewhere for later use:
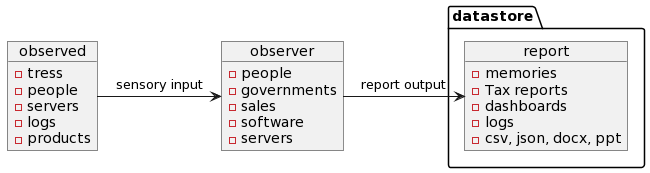
With our stored knowledge, we can assign tags to objects and recognize patterns in the input.
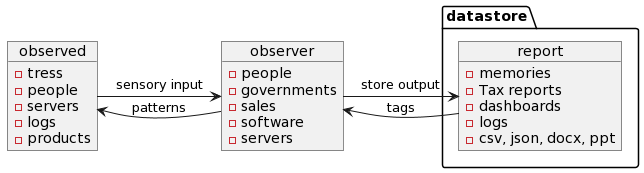
So in my definition, observability is a process that collects metrics about observed entities and creates a report about its findings.
This is a very simplified way how we build our knowledge base.
You should be able to recognize another pattern.

Software that collects metrics from a log can produce output as a log.
What does this mean?
The output of an observer can be an input for another observer and we can chain observers together. This is called piping, or pipelining.
What happens when the pipebrokes?
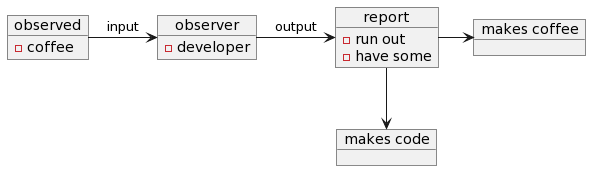
The result of a report can affect our next step. This is a trigger. When an event occurs, it can trigger an alert and motivates us to do something about it.
(BTW, have you ever heard about event-driven development? :) )
Can we have multiple observers? This way, we can gather more information parallel. Sure, why not.
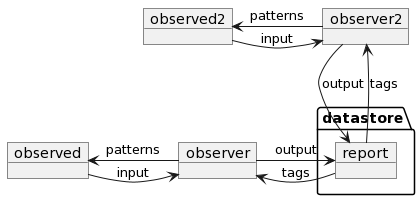
One thing I want you to remember. In this example, multiple actors build a shared knowledge base. What if one of the actors miss behaving?
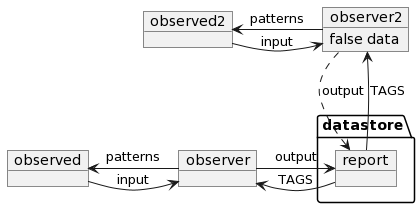
We can assign tags to miss behaving observers and limit their access to the data store.
To remember this concept, think about your loan credibility. You will lose your credit if you do not repay your loans on time. And the lender may give you less money, or they may raise your interest rate next time. (I hope I wrote this right, I’m not a native speaker.)
This is why tags play an essential role, not just as a method of how we can categorize information but to trace the source of it or limit or control access to resources. (Security :))
We can have many inputs, but if we cannot understand the pattern, then we cannot work with the information. For example, can my eyes receive ultraviolet light? Yes, it can, and it does every minute. But I don’t have a way to identify this pattern.
Let’s see a more technical example:
GET / HTTP/1.1
If you don’t know the HTTP protocol, this line means nothing to you, but if we add a pattern, it may make more sense.
"HTTP method" "path under a website" "the protocol and its version"
GET / HTTP/1.1
We see and learn patterns everywhere. But are they correct?
 Source:
https://en.wikipedia.org/wiki/Checker_shadow_illusion
Source:
https://en.wikipedia.org/wiki/Checker_shadow_illusion
A and B have identical colors in the checker shadow illusion, yet we see them differently because of our pattern recognition.
Another technical example. The following is an Apache access logline.
x.x.x.21 - - [17/Jul/2022:20:38:29 +0000] "GET / HTTP/1.1" 403 7620 "http://whois.domaintools.com/mywebsite.com" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
We can now identify GET / HTTP/1.1. This is an HTTP protocol stuff.
We see "http://whois.domaintools.com/mywebsite.com". This part is called the HTTP referrer. When we navigate from one website to another, then our browser fills this out and sends this information to the second website.
So, is this visitor come from the domaintools website?
Not necessary. If I use a “browser”, which will NOT fill it, or I tell it to fill it with random sites, then I can do interesting things. For example CVE 2006-0461
Takeaway: learning and maintaining patterns can be a challenge.
I hope what I tried to show you will help you understand and recognize the observability pattern in the future.
When I try a new tool or feature, I try to understand the different components and try to fit them into this pattern.
I see them as Lego pieces, and I can mix them and use components where it feel right.
Other definitions of Observability
Just for example, I found some definitions online.
Solarwinds
“Observability is the ability to provide insights, automated analytics, and actionable intelligence through the application of cross-domain data correlation, machine learning (ML), and AIOps across massive real-time and historical metrics, logs, and trace data.” Source: https://www.solarwinds.com/resources/it-glossary/observability
techtarger
“Observability is a management strategy focused on keeping the most relevant, important and core issues at or near the top of an operations process flow. The term is also used to describe software processes that facilitate the separation of critical information from routine information. It can also refer to the extraction and processing of critical information at the highest-level architecture of operations systems.” Source: https://www.techtarget.com/searchitoperations/definition/observability
Splunk
‘Observability is the ability to measure the internal states of a system by examining its outputs. A system is considered “observable” if the current state can be estimated by only using information from outputs, namely sensor data.’ Source: https://www.splunk.com/en_us/data-insider/what-is-observability.html
Thoughts
It’s getting late so I will not be able to create the video from the script. I took a little break and was thinking about expanding this concept on deployment, thin clients, and so on. Maybe in another post.
I will update the post with the link to the video. Cheers! ˆˆ